



The Economics of Large Language Models
August 8, 2023
A deep dive into considerations for using and hosting large language models
There have been many new exciting developments in Generative AI over the last couple of months. ChatGPT was released in late 2022 and took the world of AI by storm. In response, industries started inquiring into large language models and how to incorporate them into their business. However, in sensitive applications like healthcare, finance, and legal industries — privacy of public APIs like ChatGPT have been a concern.
However, recent innovations in open-source models like Falcon and LLaMA have made it possible to obtain ChatGPT like quality from open-source models. The benefit of these models is that unlike ChatGPT or GPT-4, the model weights are available for most commercial use-cases. By deploying these models on custom cloud provider or on-premises infrastructures, privacy concerns are alleviated — meaning that large industries can now start to seriously consider incorporating the wonders of Generative AI into their products!
So let’s go in depth on the economics of various Large Language Models (LLMs)!
GPT-3.5/4 API Costs
The ChatGPT API is priced by usage, and it costs 0.002$ for 1K tokens. Each token is roughly three-quarters a word— and the number of tokens in a single request is the sum of prompt + generated output tokens. Let’s say you process 1000 small chunks of text per day, each chunk being a page of text — so 500 words or 667 tokens and the output is also the same length — as an upper estimate. This works out to $0.002/1000×667*2*1000= ~$2.6 a day. Not bad at all!
But what happens if you are processing a million such documents a day? Then it is $2,600 per day or ~1 Million$ a year! ChatGPT goes from being a cool toy to being a major expense (and consequently one hopes — a major source of revenue) in a multi-million dollar business!
There are other models from OpenAI that are more powerful, like the 16K context version of ChatGPT or GPT-4 models that are even more powerful. The larger context here just means that you can send in more context to LLMs, and ask it to do tasks like answer questions, over longer documents. Here are the costs for 1K vs 1M requests a day based on the various OpenAI models:
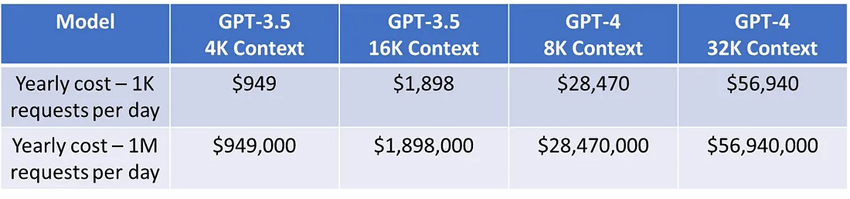
Yearly Costs Based On Usage And OpenAI Model | Skanda Vivek
As you can see — the yearly costs range from $1K-50K a year on the low usage end, depending on which model. Or from $1M-56M a year for high usage! For lower usage — in our opinion OpenAI API models make sense, due to their quality and cost effectiveness.
But for larger usage when you go to the $1M+, you need to seriously consider economic viability even if you did have that money to spare as extra change. What would make sense is if you have that sort of spare change lying around and see the value of LLMs in your industry — is to spend that money towards growing your organization to be an industry leader in LLMs in your specific area, rather than spending money purely towards sunken costs. Instead, you might use that to customize existing open-source models by fine-tuning them on industry-specific data, making you more competitive.
Another way to handle asking questions over extremely long or a large number of documents is by using Retrieval Augmented Generation (RAG) (see this Medium article) — which basically amounts to storing data in small sizeable chunks in a vector database — and using vector similarity metrics to retrieve document chunks more likely to contain information relevant to your needs.
Another possibility is to spend the money on OpenAI API costs but differentiate yourself as an innovator in how you handle RAG and the complex interface between documents and the LLM.
Build Industry-Specific LLMs Using Retrieval Augmented Generation
Organizations are in a race to adopt Large Language Models. Let’s dive into how you can build industry-specific LLMs…
Open-Source Model Hosting Costs
If you decide to host a large language model — the major costs are associated with hosting these resource intensive LLMs and hourly costs. As a rule of thumb, storing a 1B parameter in GPU memory, required for inference — costs 4 GB at 32-bit float precision, or 2 GB at 16-bit precision. By default, model weights are stored at the higher 32-bit precision, but there are techniques to store weights at 16-bit (or even 8-bit) precision, with minimal loss in response quality.

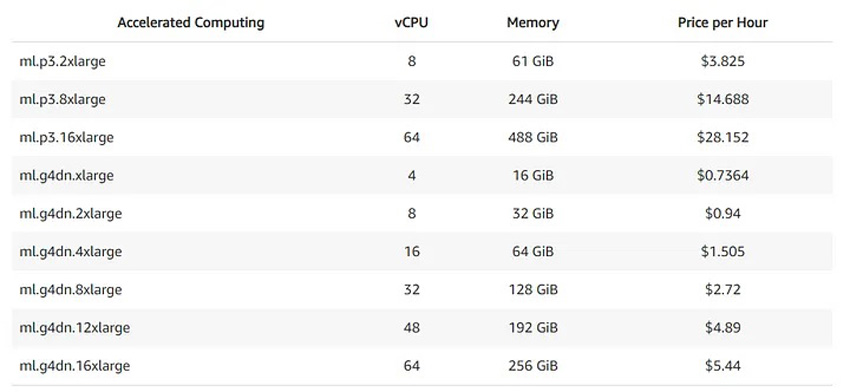
GPU RAM costs | Deeplearning.AI Generative AI with LLM Course
So for a 7 Billion parameter model like Falcon-7B or LLaMA2–7B at 16-bit precision, that would mean you need 14GB of GPU RAM. These would fit on an NVIDIA T4 GPU that has 16GB of GPU memory. You can see the pricing for a typical cloud service provider like AWS as below — the g4 instances all have a single T4 GPU, whereas the 12X large has 4 GPUs. Basically, if you want to deploy a 7B parameter model, it would cost ~2–3$/hr. As mentioned in this blog — there are costs associated with the number of requests made, but these are typically lower than endpoint costs. Roughly, this costs 0.01$ for 1000 requests, or 10$ for 1M requests.
The larger open-source models like Vicuna-33B, or LLaMA-2–70b perform better than smaller models — so you might think about deploying these larger models. However, these are more expensive in order to have the needed 100–200 GBs of GPU memory, require multiple GPUs, and cost ~20$/hr.
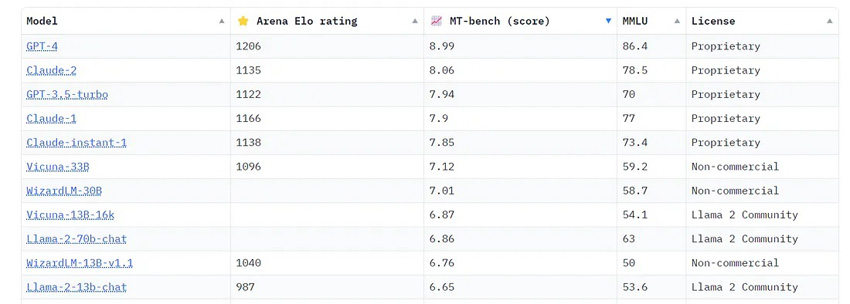
So these are the updated costs, comparing both open-source as well as the OpenAI GPT family of models:
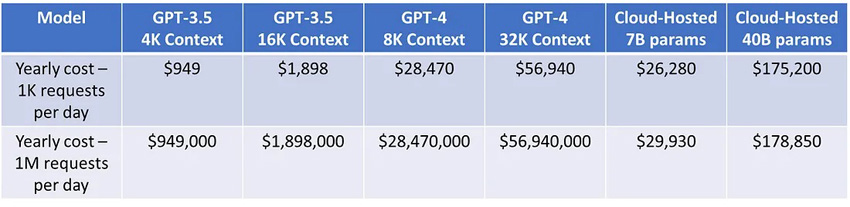
Yearly Costs Based On Usage And OpenAI/Cloud Hosted Model | Skanda Vivek
It is worth noting that while the above costs are for memory and compute, one also needs to consider other cloud related infrastructure to maintain in order to cater to network traffic/requests per second/minute. For one, you might need multiple GPUs with load balancers, to ensure low latency even during times of large load. There might be additional costs associated with availability, lower downtime, maintenance and monitoring that you need to consider based on your use-case.
On-Premises Hosting Costs
On-premises hosting is where you want to completely isolate the models and run on private servers. To do this, you need to purchase a high-quality GPU like NVIDIA A10 or A100. There is currently a shortage of these chips, and the A10 (with 24GB GPU memory) costs $3k, whereas the A100 (40 GB memory) costs $10–20k.
However, there are companies that offer pre-built products like Lambda Labs as below:
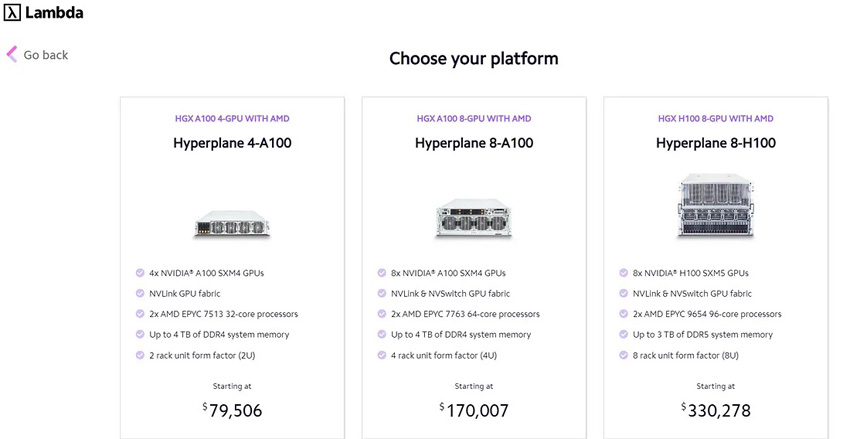
The same considerations for latency, availability, maintenance and monitoring as in cloud hosted models also apply for on-premises hosting. The one difference though is that in the event you want to start scaling up as you receive more traffic— using a cloud hosted provider would mean you can increase the resources virtually (and pay more of course), but you can’t do this on-premises, unless you physically buy more infrastructure, and of-course you are now in charge of setting everything up properly, as well as maintenance.
Final Thoughts
We have covered 3 different options in increasing difficulty levels, for deploying LLMs: using a closed LLM API like ChatGPT, hosting on a private cloud instance, and on-premises hosting. We would suggest first trying out your use case with ChatGPT/GPT-4 if you are excited to try LLMs out, but are just starting off your explorations. Once you are sure that LLMs are the way to go, you can explore the other options — which might make more sense if you have privacy concerns, or expect to be serving millions of customers in a short period — for which ChatGPT and especially GPT-4 are quite expensive. Or you might want to develop an ultra-specialized industry specific LLM, for which hosting is the first step, after which you would want to fine-tune a model on custom data.
A final option we haven’t discussed is LLM service providers that help figure out running models on cloud/on-premises stacks for companies. Snowflake for example, has introduced services to train an LLM using custom data. Databricks offers similar solutions.