


Privacy In Large Language Models
October 24, 2023
In our experience, within 5–10 minutes, potential clients mention privacy as a big concern for OpenAI based apps. Is there any hope for privately hosted LLMs?
Generative AI is taking industries by storm. Right now, the most attractive markets are saving precious human and monetary resources, using LLMs. These include replacing analysts poring through news articles or documents, revamping legacy chat systems and interactive voice response (IVR) systems, etc. The go to solution is using ChatGPT as the underlying LLM engine, and figuring out how to integrate this with business documents using retrieval augmented generation (RAG) and chat histories.
However, this leads to several privacy concerns as many organizations are not comfortable sharing their data with OpenAI. Let’s go in depth on how to make LLMs private.
3 types of LLMs by privacy
Publicly accessible APIs: Publicly accessible endpoints like OpenAI ChatGPT/GPT-4 have several advantages. They are easy to use, and as of now — are the best performing models. However, organizations are concerned with sharing data to OpenAI. Another concern is about the security of these publicly accessible endpoints.
Private cloud hosted APIs: Cloud providers like AWS, Azure, Google Cloud, etc. offer solutions for hosting open-source LLMs. However, these solutions charge hourly for hosting, and can often be expensive compared with publicly hosted APIs. See this blog below for more in depth comparisons:
The Economics of Large Language Models
A deep dive into considerations for using and hosting large language models

Another issue is figuring out how to scale cloud hosted models for quick latency and during times of large loads. Providers like OpenAI already do this in their backend while you use their public APIs, but for cloud hosted models, you need to figure this out yourself.
A potential hiccup is the difference in performance and API interface between the GPT family of models and open-source models that can be hosted on the cloud. However, OpenAI offers a neat way to use private APIs instead of the standard OpenAI publicly accessible URL, but with access to OpenAI interface. Azure, for instance, has already paved the way, offering Python-friendly integration with OpenAI endpoints. All you need to do is replace the base API and key.
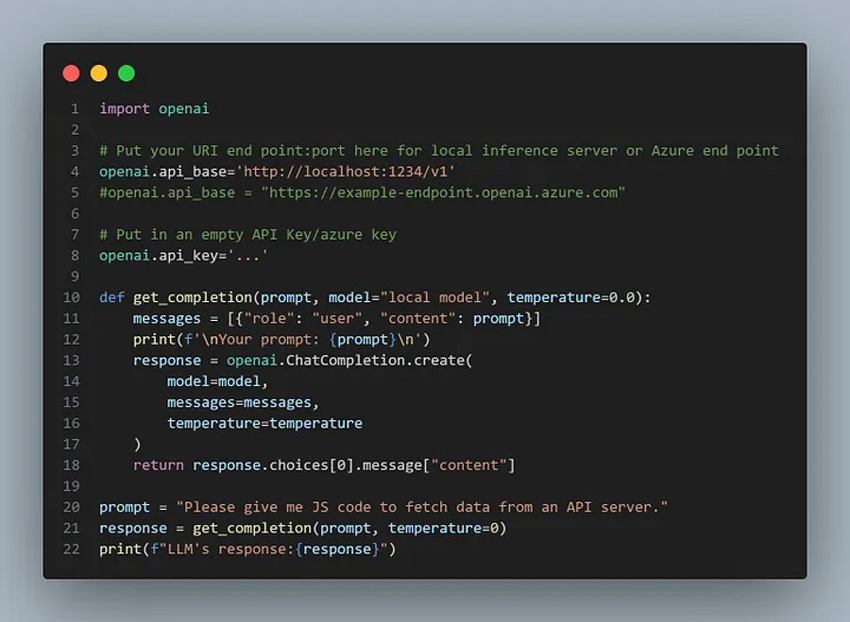
Using OpenAI API functions as wrappers around other APIs | Skanda Vivek
Yet another service called LiteLLM allows for calling all LLM APIs using the OpenAI format. However, one thing to keep in mind is that all open-source models are not for commercial use. As you can see below, some open-source models have more permissible licenses than others.
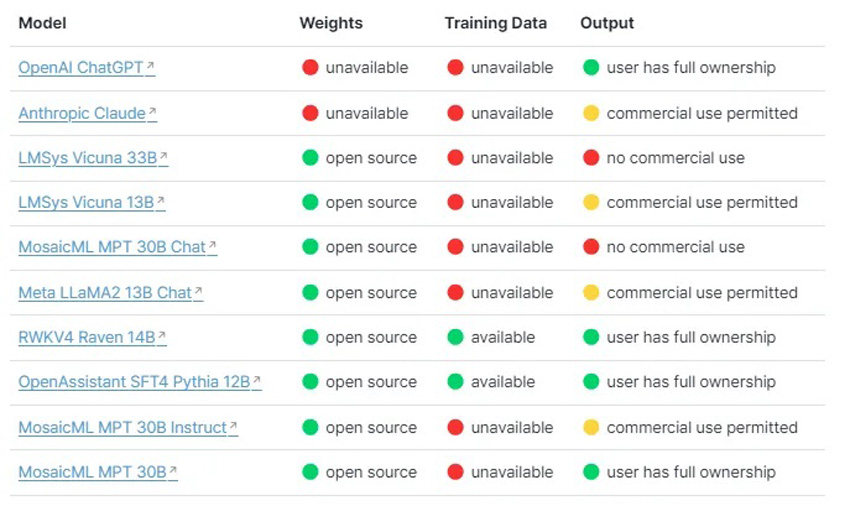
Open-Source Model Licenses | PremAI
On-premises hosting: On-premises hosting represents the most private option. Though not necessarily the most secure, as privately hosted models are susceptible to cyber-attacks especially in cases where best practices are not implemented. This represents even more of a challenge than cloud hosted LLMs due to the need for organizations to setup their own custom infrastructure for hosting large models. Typical LLMs contain 10–100Billion parameters.
Let’s calculate how much memory is needed for putting a 10 Billion parameter in memory. If each parameter is a 32-bit float (or 4 bytes), we have 40 Billion bytes in total – or 40 GB. A 1B parameter model requires 4 GB of memory, and a 100 Billion parameter model requires 400 GB. For faster inference, these need to be stored in RAM, or preferably in GPU memory – making deploying the models very expensive.
Model quantization is an new and up coming solution, aimed to solve hosting constraints. The idea is to convert a 32-bit model to lower precision — like 8 bit or 4-bit, which effectively reduces the memory. 8-bit model would take 4x less memory, making it much more affordable. Some smaller <10B parameter models then can be run locally on consumer grade CPUs or GPUs. See this article for more details:
How And Why To Quantize Large Language Models
Learn how recent advances make it possible to deploy and fine-tune LLMs with Billions of parameters on consumer…

Evaluating LLM apps
LLMs are not only fundamentally changing business directions, but also changing the way engineers build and evaluate LLM applications. Because the use-cases of these apps are often open-ended and left to the customer to interact with (e.g. chatbots) — it is hard to ensure high quality during these interactions. It is all the more important to properly evaluate self hosted or cloud hosted LLMs, since these can have quite different performance compared to the more battle tested GPT family of LLMs. See this article for more information on the intricacies in evaluating LLM Apps:
How Do You Evaluate Large Language Model Apps — When 99% is just not good enough?
LLMs are fundamentally changing the way practitioners evaluate performance . Let’s look at the recent progress towards…
Takeaways
While industries are racing to incorporate Generative AI, privacy and security remain a hot topic. In less sensitive cases and for lower tiered usage, it makes most sense to get started with ChatGPT/GPT-4 as the LLM engine for apps. However, as use-cases become more restrictive or inference costs increase due to increased usage, it becomes important to have in-place a solution for deploying more private LLMs through cloud or self hosting.
The good news is that it is relatively easy to swap out GPT-based LLMs with other open-source LLMs due to multiple providers providing API interfaces. However, it is up to the organization to ensure response quality is not diminished. It becomes embarrassing if while privacy and security improve, quality suffers. This is why it is important for organizations to slowly start building their own domain specific LLMs early on. So that in the event it makes sense to switch over from GPT to an open-source (privately hosted or cloud hosted) LLM — that transition is smooth.