



Innovations In Retrieval Augmented Generation
December 8, 2023
Retrieval Augmented Generation (RAG) offers a pathway to integrate large language models like ChatGPT/GPT-4 with custom data, but has limitations. Let’s learn how recent RAG research innovations can solve some of these.
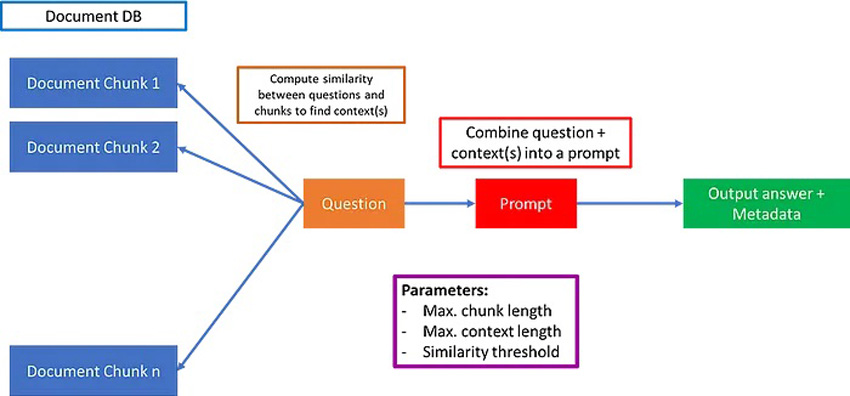
Large language models (LLMs) are all set to revolutionize the financial sector. One use-case are LLMs to pore over troves of documents and find trends in a fraction of time and at a fraction of the cost of analysts. But here’s the catch — the answers you get are only partial and incomplete many times. Take, for example, the case where you have a document containing company X’s annual revenue over the past 15 years, but in different sections. In the standard Retrieval Augmented Generation (RAG) architecture as pictured below, you typically retrieve the top-k documents, or choose documents within a fixed context length.
RAG Prototype | Skanda Vivek
However, this can have several issues. One issue is wherein the top-k documents do not contain all the answers — maybe for example only corresponding to the last 5 or 10 years. The other issue is that computing similarity between document chunks and prompt does not always yield relevant contexts. In this case, you could be getting a wrong answer.
A real issue is that you have developed your vanilla RAG app that works well in simple cases you test out — but this fails when you present this prototype to stakeholders and they ask some out of the box questions. Let’s look at a few recent RAG innovations and see how they offer solutions to the above problems.
Self-RAG
However, this can have several issues. One issue is wherein the top-k documents do not contain all the answers — maybe for example only corresponding to the last 5 or 10 years. The other issue is that computing similarity between document chunks and prompt does not always yield relevant contexts. In this case, you could be getting a wrong answer.
A real issue is that you have developed your vanilla RAG app that works well in simple cases you test out — but this The authors develop a clever way for a fine-tuned LM (Llama2–7B and 13B) to output special tokens [Retrieval], [No Retrieval], [Relevant], [Irrelevant], [No support / Contradictory], [Partially supported], [Utility], etc. appended to LM generations to decide whether or not a context is relevant/irrelevant, the LM generated text from the context is supported or not, and the utility of the generation.
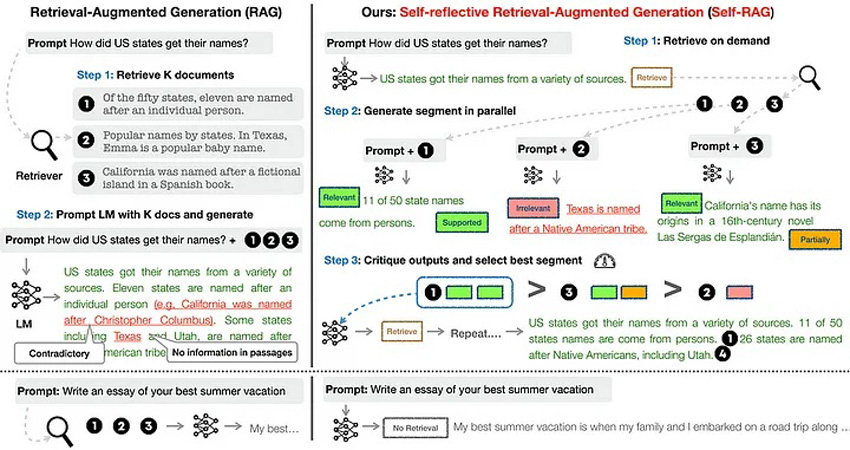
Training Self-RAG
Self-RAG was trained in a 2-step hierarchical process. In step 1, a simple LM was trained to classify a generated output (either just the prompt or prompt + RAG augmented output) and append the relevant special token at the end. This “critic model” was trained by GPT-4 annotations. Specifically, GPT-4 was prompted using a type-specific instruction (“Given an instruction, make a judgment on whether finding some external documents from the web helps to generate a better response.”)
In step 2, the generator model model, using a standard next token prediction objective, learns to generate continuations, as well as special tokens to retrieve/critique generations. Unlike other fine-tuning or RLHF methods where downstream training can impact model outputs and make future generations biased, through this simple approach, the model is trained only to generate special tokens as appropriate, and otherwise not change the underlying LM! Which is brilliant!
Evaluating Self-RAG
The authors performed a bunch of evaluations against public health fact verification, multiple-choice reasoning, Q&A, etc. There were 3 types of tasks. Closed-set tasks included fact verification and multiple-choice reasoning, and accuracy was used as the evaluation metric. Short-form generation tasks included open-domain Q&A datasets. The authors evaluated for whether or not gold answers are included in the model generations instead of strictly requiring exact matching.
Long-form generation included biography generation and long-form QA. For evaluating these tasks, the authors used FactScore to evaluate biographies — basically a measure of the various pieces of information generated, and their factual correctness. For long-form QA, citation precision and recall were used.
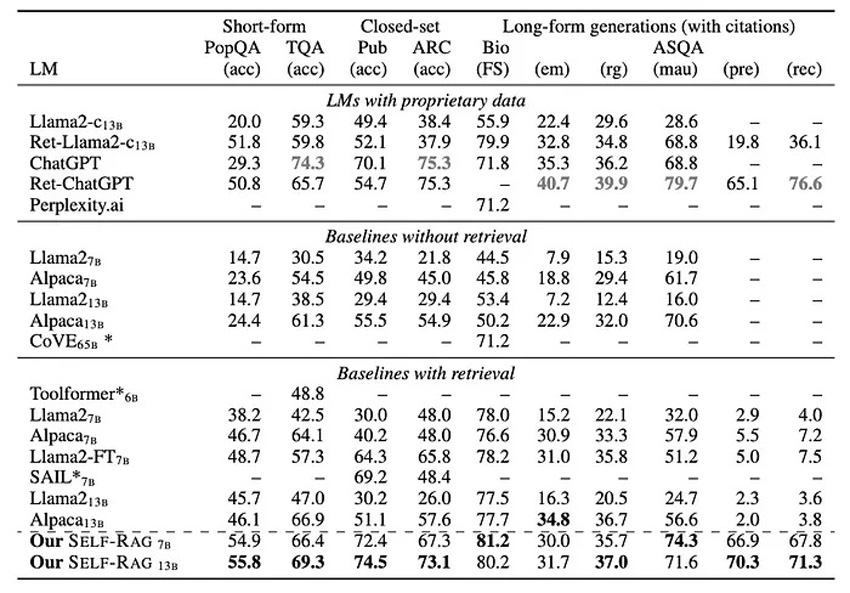
Self-RAG performs the best among non-proprietary models, and in most cases the larger 13B parameter outperforms the 7B model. It even outperforms ChatGPT in some cases.
Inference
For inference, the self-RAG repository suggests using vllm — an library for LLM inference.
After pip installing vllm, you can load in the libraries and query as follows:
from vllm import LLM, SamplingParams
model = LLM("selfrag/selfrag_llama2_7b", download_dir="/gscratch/h2lab/akari/model_cache", dtype="half")
sampling_params = SamplingParams(temperature=0.0, top_p=1.0, max_tokens=100, skip_special_tokens=False)
def format_prompt(input, paragraph=None):
prompt = "### Instruction:\n{0}\n\n### Response:\n".format(input)
if paragraph is not None:
prompt += "[Retrieval]<paragraph>{0}</paragraph>".format(paragraph)
return prompt
query_1 = "Leave odd one out: twitter, instagram, whatsapp."
query_2 = "Can you tell me the difference between llamas and alpacas?"
queries = [query_1, query_2]
# for a query that doesn't require retrieval
preds = model.generate([format_prompt(query) for query in queries], sampling_params)
for pred in preds:
print("Model prediction: {0}".format(pred.outputs[0].text))
For a query that requires retrieval, you can supply the necessary information as a string in the example below.
paragraph="""Llamas range from 200 to 350 lbs., while alpacas weigh in at 100 to 175 lbs."""
def format_prompt_p(input, paragraph=paragraph):
prompt = "### Instruction:\n{0}\n\n### Response:\n".format(input)
if paragraph is not None:
prompt += "[Retrieval]<paragraph>{0}</paragraph>".format(paragraph)
return prompt
query_1 = "Leave odd one out: twitter, instagram, whatsapp."
query_2 = "Can you tell me the differences between llamas and alpacas?"
queries = [query_1, query_2]
# for a query that doesn't require retrieval
preds = model.generate([format_prompt_p(query) for query in queries], sampling_params)
for pred in preds:
print("Model prediction: {0}".format(pred.outputs[0].text))[Irrelevant]Whatsapp is the odd one out.
[No Retrieval]Twitter and Instagram are both social media platforms,
while Whatsapp is a messaging app.[Utility:5]
[Relevant]Llamas are larger than alpacas, with males weighing up to 350 pounds.
[Partially supported][Utility:5]In the above example, for the first query (related to social media platforms) the paragraph context is irrelevant, as reflected by the [Irrelevant] token at the beginning of the retrieval. The external context is however, relevant to the second query (related to llamas and alpacas). As you can see, it includes this information in the generated context, marked by the [Relevant] token.
But in the example below, the context “I like Avocado.” is unrelated to the prompt. As you can see below, the model prediction starts of as [Irrelevant] for both queries, and just uses internal information to answer the prompt.
paragraph="""I like Avocado."""
def format_prompt_p(input, paragraph=paragraph):
prompt = "### Instruction:\n{0}\n\n### Response:\n".format(input)
if paragraph is not None:
prompt += "[Retrieval]<paragraph>{0}</paragraph>".format(paragraph)
return prompt
query_1 = "Leave odd one out: twitter, instagram, whatsapp."
query_2 = "Can you tell me the differences between llamas and alpacas?"
queries = [query_1, query_2]
# for a query that doesn't require retrieval
preds = model.generate([format_prompt_p(query) for query in queries], sampling_params)
for pred in preds:
print("Model prediction: {0}".format(pred.outputs[0].text))Model prediction: [Irrelevant]Twitter is the odd one out.[Utility:5]
[Irrelevant]Sure![Continue to Use Evidence]
Alpacas are a much smaller than llamas.
They are also bred specifically for their fiber.[Utility:5]Self-RAG has several advantages over the vanilla LLM.
- Adaptive Passage Retrieval: By this, the LLM can keep retrieving context until all the relevant context is found (within the context window of course.)
- More relevant retrieval: A lot of times, embedding models are not the best at retrieving relevant context. Self-RAG potentially solves this with the relevant/irrelevant special token.
- Beats other similar models: Self-RAG beats other similar models, and also surprisingly beats ChatGPT in many tasks. It would be interesting to do a comparison with data that ChatGPT has not been trained on — so more proprietary, industrial data.
- Doesn’t change underlying LM: For me this is a huge upsell — as we know how fine-tuning and RLHF can lead to biased models very easily. Self-RAG seems to solve this by adding special tokens, and otherwise keeping text generation the same.
Re-ranking Models
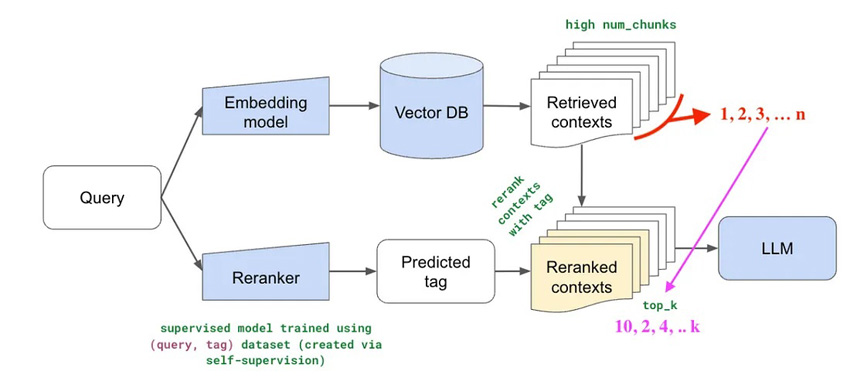
Re-ranking is a simple (yet powerful) idea, compared to other RAG innovations. The idea is that you retrieve a large number of documents (say n=25) first. Next, you train a smaller reranker model to select the top k (say 3) documents out of the 25, and feed that as the LLM context. This is a pretty cool technique, and conceptually makes a lot of sense — since the underlying embedding model to obtain the top-k contexts is not trained on knowledge retrieval per say, so it makes a lot of sense to train a smaller re-ranker model for specific RAG scenarios.
Forward-Looking Active Retrieval Augmented Generation (FLARE)
FLARE is used to handle cases where you want answers to be correct, and up to date — for which it makes sense to augment LLM knowledge with a real-time updated knowledge hub (the Internet). As you can see below, one solution is to combine iteratively internet searches, and LLM knowledge.
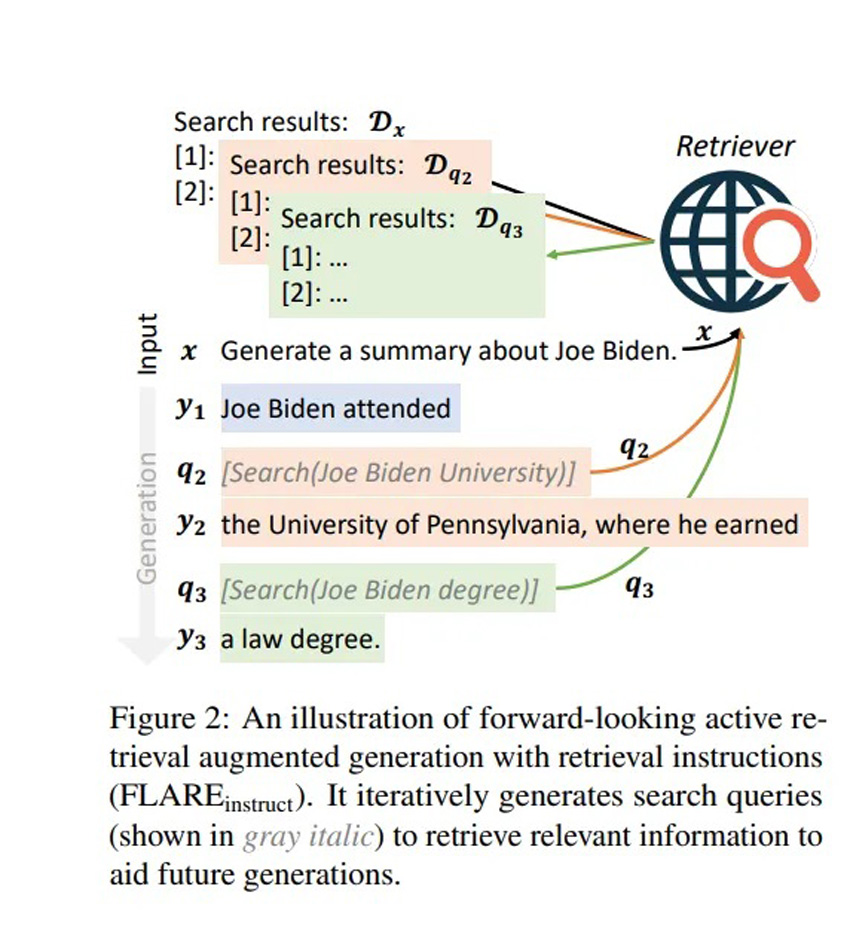
In this workflow, first the user asks a question, and the LLM generates an initial partial sentence. This partial generation acts as a seed for an Internet search query (e.g. Joe Biden attended [X]). The result from this query is then integrated into the LLM response, and this process of continuous search and update continues, until the end of the generation.
System 2 Attention (S2A)
S2A — released by META a couple of weeks back tries to solve the problem of spurious context with a little more finesse. Instead of marking contexts as relevant/irrelvant as in self-RAG or re-ranking, in S2A context is regenerated to remove noise and ensuring relevant information remains.

S2A works through a specific instruction that requires the LLM to regenerate the context, extracting the part that is beneficial for providing relevant context for a given query as below.

Overall, S2A has a ~15% higher accuracy than traditional RAG implementations from multiple evaluations.
Multimodal RAG
Finally, I want to discuss (in my opinion) one of the most exciting RAG directions that potentially results in an explosion of industry use-cases, multimodal RAG that can search across disparate types of data — text, vision, audio, etc.
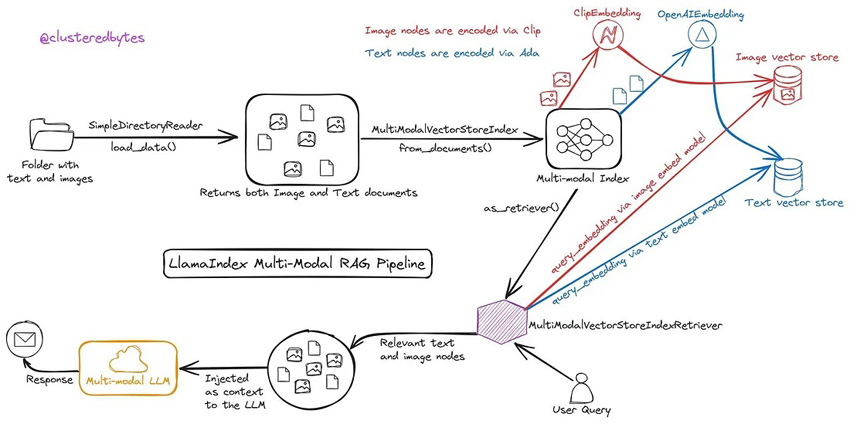
The architecture above uses Contrastive Language–Image Pretraining (CLIP) embeddings, that can generate simultaneous embeddings for both image and text. The embeddings can be used to extract the top-k contexts (image+text) that are most similar to the question. The next step is to combine these contexts and input and feed into a multimodal model like GPT-V or LLaVa to synthesize the final response.
Takeaways
We’ve gone through a number of innovative approaches to improve RAG, including Self-RAG, Reranking, FLARE, S2A, and Multimodal RAG. These are all innovations within the past couple of months, and are much needed as RAG use-cases continue to explode in the industry.
Exciting times ahead!