



Designing LLMs with C.A.R.E.
September 5, 2023
Amid the extensive discussion within public forums concerning the technical facets of Large Language Models (LLMs), encompassing both their applications and cost implications, a notable absence prevails: a universally adopted collection of metrics that could serve as a valuable guide for decision makers and project managers in gauging the advancement and effectiveness of projects grounded in LLMs.
Initiating an AI-based project invariably demands substantial resources. This article endeavors to introduce 4 metrics accessible to leaders and decision makers, facilitating their evaluation of progress in projects hinged on LLMs.

Leveraging EMAlpha’s extensive expertise in training and employing Large Language Models (LLMs) for financial applications, the EMAlpha team has identified four metrics tailored for the use of decision makers and project leaders. The development of a typical LLM-based application encompasses several stages of progression, spanning from its conceptualization to its ultimate delivery. As the project unfolds across these phases, there are four key metrics that can be employed at the overarching level to assess the project’s advancement. In order for an LLM-based application to qualify as effective, the final product should exhibit the following characteristics:
Continuous: The application’s behavior should be consistently continuous. Minor alterations in user queries should elicit commensurate adjustments in the application’s responses.
Accurate: The application should consistently generate accurate outcomes. While this requirement might seem inherent, it is not an assured outcome from LLM-based applications.
Repeatable: The application’s responses should be replicable. Repeated questions should invariably yield identical responses.
Economical: Finally, the selection of the LLM and the project’s blueprint should meticulously consider the associated costs. A judicious project design can significantly curtail expenses.
Continuous
The LLM should generate consistent responses for queries with similar structures. Gradual modifications to a query ought to result in gradual adjustments within the response. In essence, the LLM should exhibit a significant level of stability and continuity in its response patterns.
Consider posing similar yet slightly varied questions to two individuals. As you engage with them, you’ll notice that the first person consistently adjusts their responses to match the subtle changes in the queries. This highlights their coherence and adaptability. However, the second person’s replies exhibit a tendency to wander off-topic and significantly diverge, showcasing a lack of consistency. Consequently, the level of trustworthiness attributed to the second person’s answers would be notably lower compared to the higher level of trust placed in the first person’s responses.
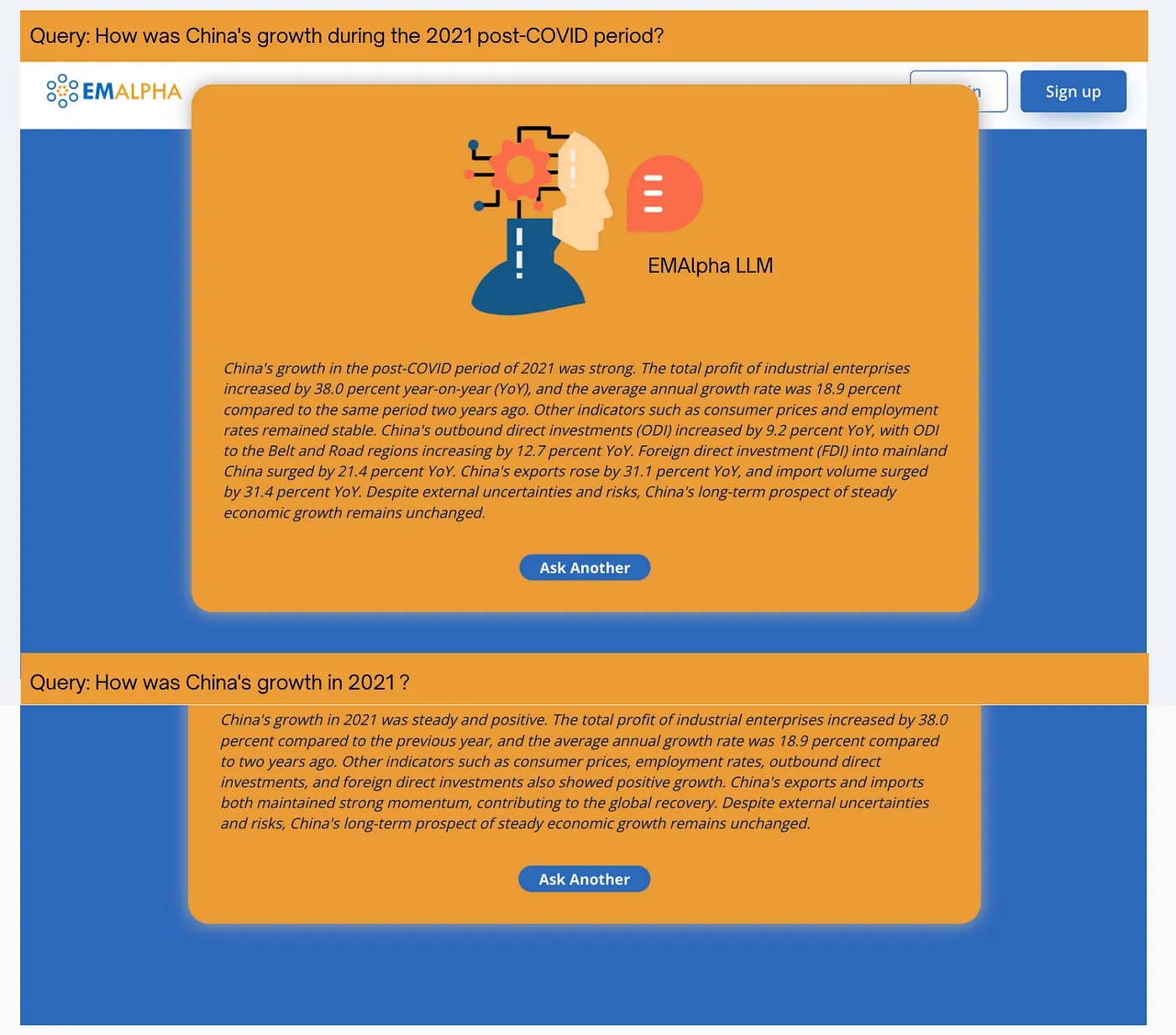
Fig. 1: Two slightly different questions as posed to EMAlpha’s LLM-based application along with the responses.
This notion of continuity is essential for any query — response interaction between two human beings. The same requirement also holds for LLMs. Fig. 1 shows EMAlpha’s LLM based application that can receive queries regarding China’s economy from 2010 onwards. It shows two responses to two quite similar queries: “How was China’s growth during the 2021 post-COVID period?” and “How was China’s growth in 2021?”. The two responses generated with EMAlpha’s LLM application are quite similar. This is the expected behavior.
Fig.2 shows the responses to the exact same two queries when posed to a generic untuned LLM. The responses are not wrong, but they are quite dissimilar in structure. A slight change in the query should not lead to such a significant change in response.
There are two primary reasons which can make the response discontinuous in the sense described in Figs. 1 and 2:
a) Insufficient model training and unsatisfactory prompt engineering: This can leave the LLM “clueless” about how to respond to similar queries.
b) Inefficient data storage architecture: Even if the LLM is trained to a satisfactory level, the data storage design and the mode of interaction between the LLM and the data store can lead to an unstable and discontinuous behavior of the LLM-based application.
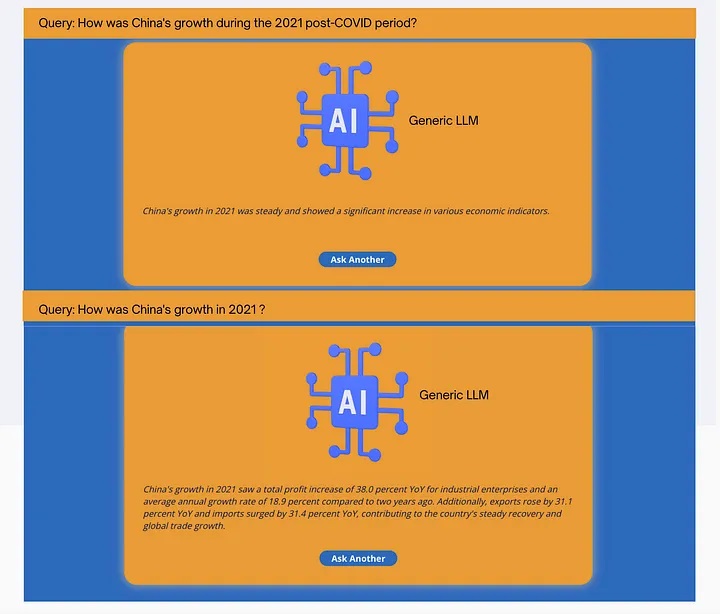
Fig. 2: Two slightly different questions as posed to a generic untuned LLM-based application along with the responses.
Accurate
Every query directed at the LLM should yield an accurate response. Ensuring response accuracy necessitates thorough LLM training and a meticulous approach to designing document data storage.
When working with applications that necessitate training the LLM on an extensive collection of documents, meticulous consideration must be devoted to the arrangement and format of these documents. It’s imperative to ascertain whether the documents solely consist of textual content or if they also encompass supplementary elements like tables and charts.
The process of extracting information from these documents demands a cautious approach, and the collated data should be adeptly organized within well-structured databases. This meticulous handling of document information is crucial to make sure the precision and reliability of the LLM’s generated responses.
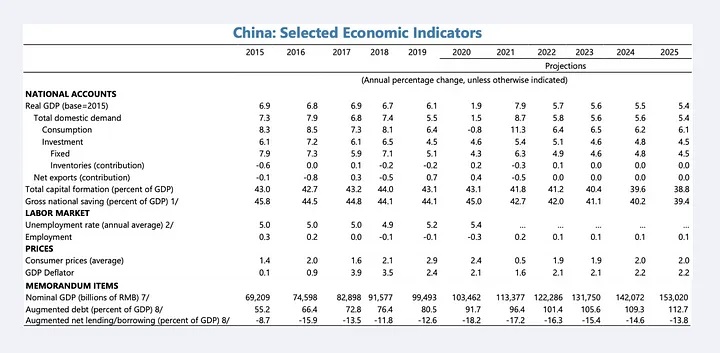
Fig. 3: China’s economic indicators from its 2015 IMF Article IV report. (Source: IMF)
Fig. 3 shows a section of a document containing information about China’s economic metrics in tabular format. The GDP is shown as 69,209 billion RMB for the year 2015 in the table. However, in Fig. 4, a generic LLM-based chatbot application responds with a figure of 82,898 billion RMB, which is the figure for the year 2017 in the table.
The reason for this inaccurate answer is the lack of fidelity in the data transfer between the table embedded in the document, and the database table housing the scraped document data available to the LLM queries.
This seemingly simple example illustrates an important aspect of using LLMs for the purpose of document querying and text summarization. Before an LLM can interact with the information, the information from documents is typically stored in databases in the form of NLP embeddings. The steps involved are the following:
- Data Scraping: Data is scraped from documents using one of the various open source or paid applications.
- Data Storage: The scraped information is then stored in cloud or on-premise databases, preferably as NLP embeddings (mathematical representations of the natural language information).
- Query Formation: Using appropriate business logic, the user query is combined with the appropriate business context to create the query to be sent to the LLM.
- Response Generation: The LLM then returns the appropriate response to the user query with proper context awareness.

Fig. 4: Inaccurate response by a generic LLM based application when queried about information shown in the document in Fig. 3.
All of these 4 steps have to function correctly to get an accurate answer to a user query. While a lot of attention has been given to LLM training and prompt engineering in public discussions, the importance of the first two steps — data scraping and data storage — must not be underestimated.
A typical enterprise use case can involve millions of documents, with various formats, containing different types of informations for different end-users. The information must be stored in a well designed database before an LLM can interact with information. In our experience, this data scraping and data storage decision can have an outsized impact on the quality of the application’s responses.
Repeatable
Consistency and repeatability in LLM responses is essential: posing the same question ought to consistently and repeatedly yield the same answer.
Although the need for repeatability might appear self-evident, all LLMs incorporate a “creativity” parameter. Across an extensive array of configurations, LLMs can exhibit considerable creativity, offering variations in responses to identical questions. This attribute proves advantageous in artistic applications of LLMs. Nevertheless, for numerous business contexts, this feature proves less desirable. In a business application setting, users typically anticipate consistent answers to identical questions.
Figs. 5 and 6 illustrate how repeatability can be a desired feature of LLM response. Both Figs. 5 and 6 involve the user asking the same question: “Give a 500 word summary of China’s GDP, as per IMF, for the year 2021.”.
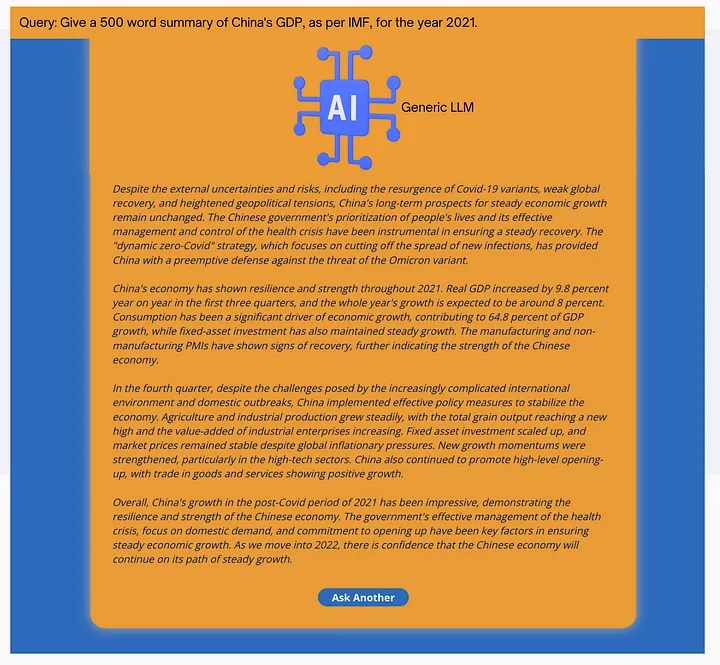
Fig. 5: Lack of repeatability in a generic LLM based application. Figures 5 and 6 shpw different responses for the same user query.

Fig. 6: Lack of repeatability in a generic LLM based application. Figures 5 and 6 shpw different responses for the same user query.
However, the response is somewhat different between the two. While the overall content of both the responses is similar, a user who asks the same question in quick succession is likely to express dissatisfaction towards such a response feature. Such non-uniform response can especially be problematic in time-sensitive applications. An execution trader or a portfolio manager in an asset management firm is likely to demand a very high degree of uniformity in repeated responses to the same question.
LLM responses can be made consistent and repeatable by tuning parameters which allow for uniformity of response. A non-zero temperature parameter, for example, will lead to non-repeatable answers.
Aside from the native LLM parameters, there can also be solution architecture decisions which can make repeatability easy or difficult. As discussed in previous sections, in any practical application, the LLM tuning process cannot be considered in isolation from the data architecture decisions.
Economical
The cost associated with LLM training, tuning, and architecture can greatly vary depending on the specific use case. Therefore, careful design is of paramount importance to ensure that costs remain in harmony with the overarching business objectives.
Before incorporating an LLM into a business use case, several factors demand careful consideration. What precisely is the intended use case? To what extent is contextual awareness crucial for achieving reasonably precise query responses? How urgent is the requirement for swift responses? Can some of the LLM’s load be alleviated through strategic data storage and architectural planning?
Fig. 7 presents an overview of indicative costs associated with LLM design, encompassing model selection, context awareness, cloud hosting, and the quantity of tuning parameters.
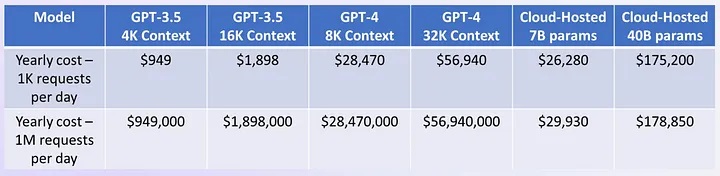
Fig. 7: An overview of indicative costs associated with LLM design, encompassing model selection, context awareness, cloud hosting, and the quantity of tuning parameters.
In the realm of text summarization and knowledge discovery applications, latency might not hold the highest priority. However, in contexts linked to time-critical trade execution, latency can indeed take on paramount significance.
Based on the insights gained from the EMAlpha team’s hands-on involvement, the expenses tied to LLM-based application designs can be substantially diminished through the adept utilization of (a) domain expertise and (b) astute data architecture. Domain knowledge guarantees the exclusion of design elements that could be theoretically significant yet prove superfluous in practical terms.
As one can see from Fig. 7 — the yearly costs range from $1K-50K a year on the low usage end, depending on which model. Or from $1M-56M a year for high usage.
LLM Economics and the Open-source vs Closed-source decisions:
For situations of limited usage, it is advisable to consider the application of paid services such as OpenAI or Bard API models due to their recognized quality and cost-effectiveness for low scale usage.
However, when dealing with substantial usage, surpassing the threshold of $1 million, careful deliberation on economic feasibility becomes imperative, even if the monetary resources are available as expendable surplus. The prudent course of action involves considering the allocation of such financial resources to propel the expansion of one’s organization into an industry leader within the domain of LLMs in the specific field.
This approach entails investing in organizational growth, rather than exclusively channeling funds towards unrecoverable expenses. Redirecting these resources can involve the customization of pre-existing open-source models through the process of fine-tuning, employing industry-specific data sets to enhance competitive advantage.
An alternative strategy to address the challenge of processing extensive inquiries spanning a significant volume of documents is the adoption of Retrieval Augmented Generation (RAG) methods. These approaches have been expounded upon in previous works. The fundamental premise involves segmenting data into manageable, compact units within a vector database. By utilizing vector similarity metrics, the retrieval process becomes optimized, aiding in the identification and retrieval of document segments that are more likely to contain pertinent information aligned with specific requirements.
Conclusion
The aforementioned issues have an impact on all LLM AI models and each LLM project. The EMAlpha team employs a meticulously developed approach that factors in the business quandary, data storage and infrastructure design, as well as the trade-offs between cost and design considerations. The utilization of the C.A.R.E. criteria equips decision-makers with a structured framework for evaluating project advancement.
Just like any project involving large-scale AI applications, embarking on LLM (Large Language Model) projects requires a substantial initial investment in terms of both financial resources and manpower. For corporate teams, it’s essential to carefully consider the advantages and disadvantages of conducting the project in-house versus collaborating with an external vendor possessing expertise in LLMs.
Once this pivotal decision is reached, the C.A.R.E. criteria, elucidated within this document, furnish a comprehensive framework for high-level decision-makers to gauge the progress of the LLM project. These criteria can be readily embraced by business leaders who may lack profound expertise in AI or LLMs.
To clarify, the C.A.R.E. framework addresses LLM-specific challenges that impact all LLMs and their respective projects or teams. Precise calibration of AI models is imperative, necessitating technology teams to craft robust data storage and infrastructure architectures that facilitate seamless AI utilization while keeping costs manageable.
Fig. 8: Objectives to keep track of during the LLM project execution.
The EMAlpha team is dedicated to the following objectives:
a) Commencing with domain experts with right skills to establish a vital connection between the business requisites and the LLM solution. A good grasp of knowledge-content increases the chances of creation of good AI-driven knowledge solutions.
b) Thoughtfully devising data storage strategies and establishing infrastructure architectures that are attuned to the intricacies of the business challenge at hand. This approach takes into account the strengths and limitations of LLMs as well as the associated economic considerations.
c) Deliberately selecting models that harmonize with the specific business demands. Given the continuous evolution of language models and their eventual obsolescence, it is crucial to have a well-structured strategy and roadmap for the “model evolution” and its ramifications on business applications.
d) Lastly, but certainly not least, maintaining meticulous financial oversight and harnessing sound architecture to mitigate the workload on LLMs, consequently optimizing operational efficiency.